Akár a negyedére is csökkentheti a memóriafelhasználást egy új LLM optimalizálási technika

A tokiói székhelyű Sakana AI startup kutatói egy olyan új technikát fejlesztettek ki, amely lehetővé teszi a nyelvi modellek hatékonyabb memóriahasználatát, így segítve a vállalkozásokat a nagy nyelvi modellek (LLM) és más Transformer-alapú modellekre épülő alkalmazások fejlesztési költségeinek csökkentésében. Az „univerzális transzformátor memória” elnevezésű technika speciális neurális hálózatok segítségével optimalizálja az LLM-eket, közben megtartja a fontos információ bitjeit, és eldobja a felesleges részleteket a kontextusukból.
A Transformer-memória optimalizálása
Az LLM-ek gerincét alkotó Transformer-modellek válaszai a „kontextusablakuk” tartalmától függnek – vagyis attól, hogy mit kapnak bemenetként a felhasználóktól.
A kontextusablak a modell munkamemóriájának tekinthető. A kontextusablak tartalmának finomhangolása óriási hatással lehet a modell teljesítményére, ami a „prompt engineering” egész területét hívta életre.
A jelenlegi modellek nagyon hosszú kontextusablakokat támogatnak, amelyek több százezer vagy akár milliónyi tokent tartalmaznak (a felhasználók által a súgókba beírt szavak, szórészletek, kifejezések, fogalmak és számok számszerű ábrázolása az LLM-ben).
Ez lehetővé teszi a felhasználók számára, hogy több információt zsúfoljanak bele a promptokba. A hosszabb bejegyzések azonban magasabb számítási költségeket és lassabb teljesítményt eredményezhetnek. A promptok optimalizálása a felesleges tokenek eltávolítása érdekében a fontos információk megtartása mellett csökkentheti a költségeket és növelheti a sebességet. A jelenlegi prompt-optimalizálási technikák erőforrás-igényesek, vagy a felhasználóknak kézzel kell tesztelniük a különböző konfigurációkat a promptok méretének csökkentése érdekében.
Neurális figyelmi memóriamodulok
Az univerzális Transformer-memória a felszólításokat neurális figyelemmemória-modellek (NAMM-ek) segítségével optimalizálja. Ezt olyan egyszerű neurális hálózatokkal végzi el, amelyek eldöntik, hogy az LLM memóriájában tárolt minden egyes adott tokent „megjegyezzenek” vagy „elfelejtsenek”.
„Ez az új képesség lehetővé teszi a transzformátorok számára, hogy a nem hasznos vagy felesleges részleteket elvessék. Egyúttal a legkritikusabb információkra összpontosítanak, ami szerintünk kulcsfontosságú a hosszú kontextusú gondolkodást igénylő feladatokhoz.” – írják a kutatók.
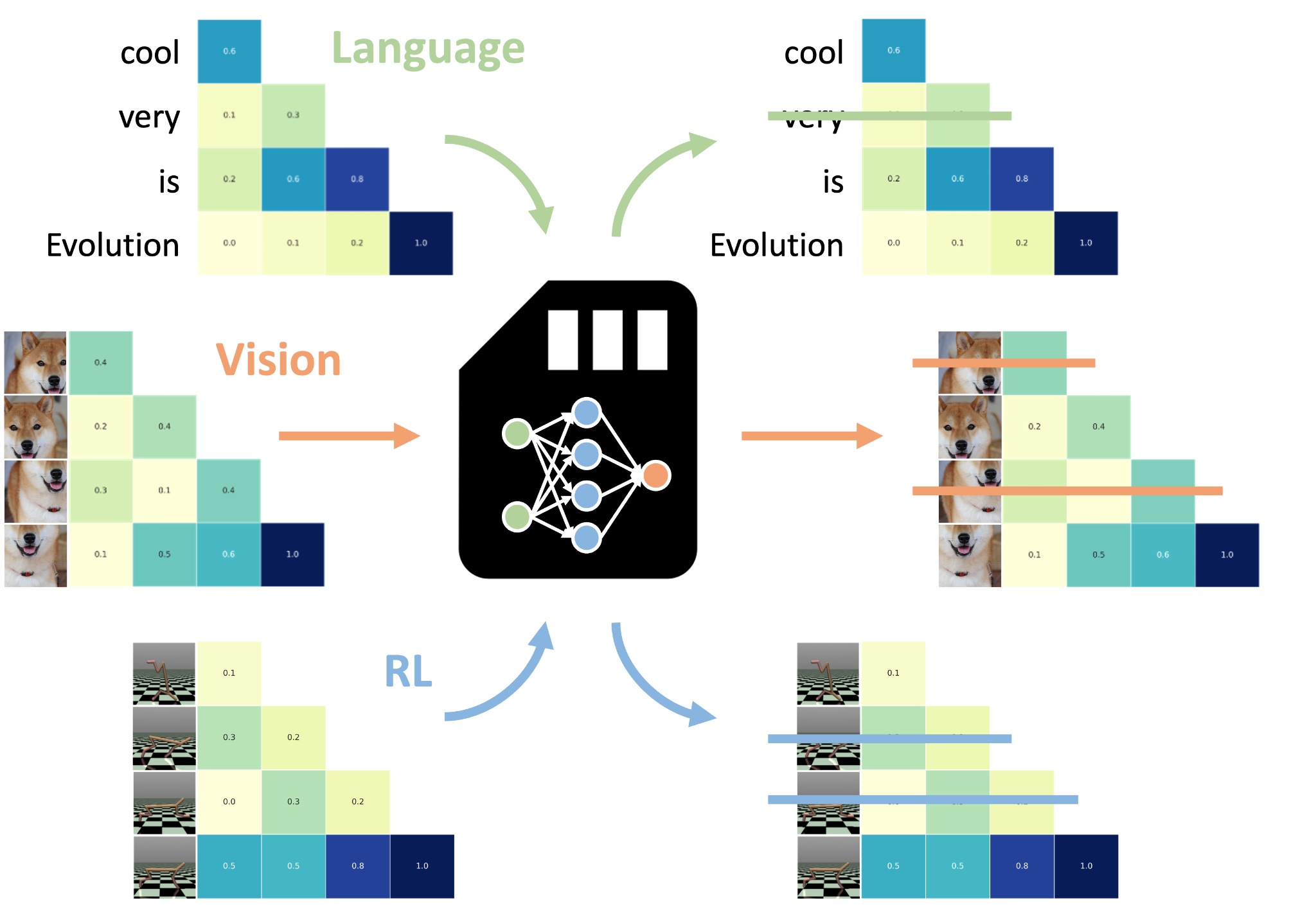
A NAMM-eket az LLM-től elkülönítve képzik ki, és következtetéskor kombinálják az előre betanított modellel, ami rugalmassá és könnyen alkalmazhatóvá teszi őket. Ugyanakkor hozzáférésre van szükségük a modell belső aktivációihoz. Ez azt jelenti, hogy csak nyílt forráskódú modellekhez alkalmazhatók.
A Sakana AI által kifejlesztett más technikákhoz hasonlóan a NAMM-eket is evolúciós algoritmusok segítségével képzik ki a gradiens alapú optimalizálási módszerek helyett. Az evolúciós algoritmusok a legjobban teljesítő modellek iteratív mutációjával és próbálgatással történő kiválasztásával optimalizálják a NAMM-okat a hatékonyság és a teljesítmény szempontjából. Ez különösen fontos, mivel a NAMM-ek egy nem differenciálható célt próbálnak elérni: a tokenek megtartását vagy eldobását.
A NAMM-ek az LLM-ek figyelmi rétegein működnek, a Transformer architektúra egyik kulcsfontosságú komponensén, amely meghatározza az egyes tokenek kapcsolatait és fontosságát a modell kontextusablakában. A figyelem értékei alapján a NAMM-ek meghatározzák, hogy mely tokeneket kell megtartani, és melyeket lehet eldobni az LLM kontextusablakából. Ez a figyelemalapú mechanizmus lehetővé teszi, hogy egy betanított NAMM-et különböző modelleken további módosítás nélkül használjunk. Például egy csak szöveges adatokon képzett NAMM további képzés nélkül alkalmazható látás vagy multimodális modellekre.
Univerzális memória működés közben
Az univerzális transzformátoros memória koncepciójának működés közbeni teszteléséhez a kutatók egy NAMM-ot képeztek ki egy nyílt forráskódú Meta Llama 3-8B modellre. Kísérleteik azt mutatják, hogy a NAMM-ekkel a Transformer-alapú modellek jobban teljesítenek a természetes nyelvi és kódolási problémákon, nagyon hosszú szekvenciákon. Eközben a felesleges tokenek elvetésével a NAMM lehetővé tette az LLM modell számára, hogy a feladatok végrehajtása során a gyorsítótár memóriájának akár 75%-át is megtakarítsa.
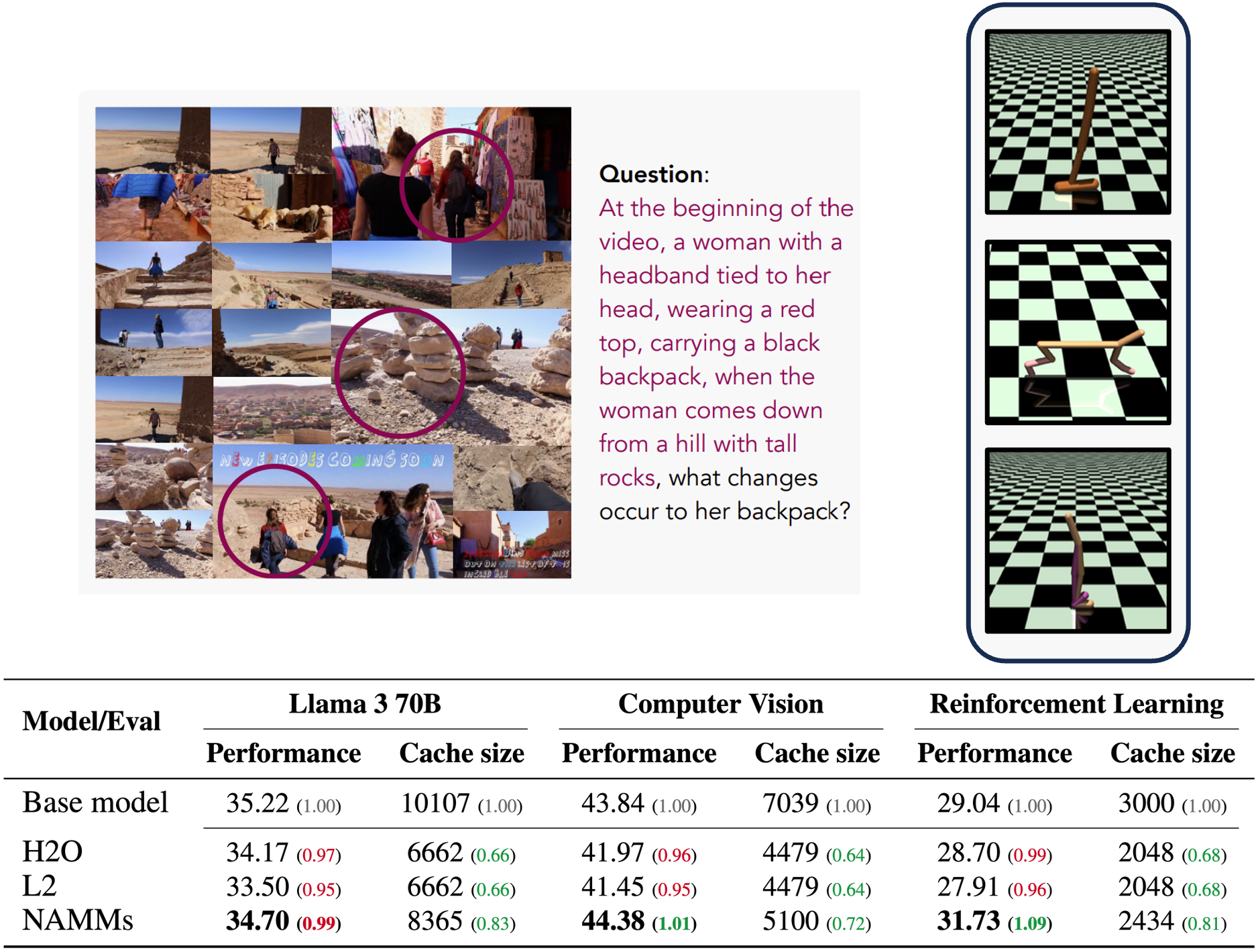
A modellt a Llama 70B változatán, valamint más modalitásokhoz és feladatokhoz tervezett Transformer-modelleken is tesztelték, mint például a Llava (számítógépes látás) és a Decision Transformer (megerősítéses tanulás).
„A NAMM-ek még ezekben a nem elosztott beállításokban is megőrzik előnyeiket azáltal, hogy olyan tokeneket dobnak ki, mint a felesleges videoképek és a szuboptimális cselekvések. Ezzel lehetővé válik, hogy az új alapmodellek a teljesítmény javítása érdekében a legrelevánsabb információkra összpontosítsanak.” – írják a kutatók.
Feladatfüggő viselkedés
Egy másik érdekes eredmény, hogy a NAMM-ok automatikusan a feladat függvényében alakítják viselkedésüket.
Például a kódolási feladatok esetében a modell elveti a tokenek egybefüggő darabjait, amelyek megfelelnek a megjegyzéseknek és a kód végrehajtását nem befolyásoló szóközöknek.
Másrészt a természetes nyelvi feladatoknál a modell elveti azokat a tokeneket, amelyek nyelvtani redundanciát jelentenek, és nem befolyásolják a szekvencia jelentését.
A kutatók közzétették a saját NAMM-ok létrehozásához szükséges kódot. Az olyan technikák, mint az univerzális transzformációs memória, nagyon hasznosak lehetnek a több millió token feldolgozását végző vállalati alkalmazások számára. Ezáltal a sebességnövekedés és a költségcsökkentés előnyeit élvezhetik. A képzett NAMM újrafelhasználhatósága emellett sokoldalúan használható eszközzé teszi azt a vállalat különböző alkalmazásaiban.
A jövőre nézve a kutatók fejlettebb technikákat javasolnak, például a NAMM-ek használatát az LLM-ek képzése során, hogy tovább bővítsék memóriaképességeiket.
„Ez a munka még csak a memóriamodellek új osztályában rejlő lehetőségek kiaknázásának kezdetét jelenti. Ezek várhatóan számos új lehetőséget kínálhatnak a transzformátorok jövőbeli generációinak fejlesztéséhez.” – írják a kutatók.