Közzétette a Twitter a posztajánló algoritmusát
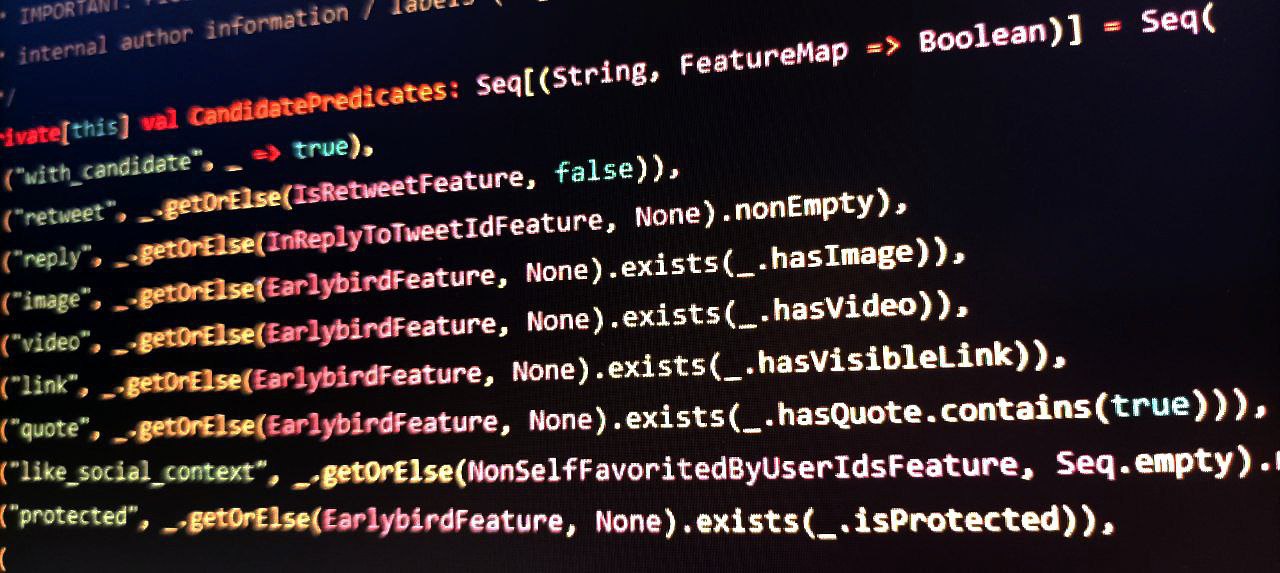
Miközben a legtöbb techóriás továbbra is szigorú titokban tartja, hogy mi alapján dönti el, mit látnak a felhasználói, a Twitter szinte a teljes algoritmusát felfedte. Legalábbis ha hihetünk a vállalat nemrég közzétett kódrészleteinek.
Amikor Elon Musk korábban bejelentette a Twitter felvásárlását, ígéretei között szerepelt, hogy nyílt forráskódúvá teszi annak algoritmusát is. A GNU Affero General Public License v3.0 licenc alatt tegnap közzétett kódrészlet betekintést enged azokba a tényezőkbe, amelyek meghatározzák, hogy egy tweet milyen valószínűséggel jelenik meg egy adott felhasználó hírfolyamában.
Egy kapcsolódó blogbejegyzésben a Twitter fejlesztőcsapata megjegyezte, miszerint a tweetek relevanciájának meghatározása számos egyéb szolgáltatástól és folyamattól függ. A rendszer alapvetően úgy működik, hogy minden egyes hírfolyamfrissítésnél a több százmillió bejegyzésből kiválasztja az 1500 legjobbat.
Ezeknek legnagyobb forrását értelemszerűen olyan tweetelők adják, akiket a felhasználó maga is követ. Talán az sem meglepő, hogy ezen belül a legtöbb poszt azoktól jelenik meg, akiknek szerzője iránt a felhasználó a leginkább elkötelezett. Ha olyantól látunk tweetet, akit nem követünk, akkor annak szerzője nagy valószínűséggel hasonló személyeket követ és hasonló tweeteket posztol, mint mi.
Politikai hovatartozást is figyelnek
Ennél talán érdekesebb (de továbbra sem meglepő), hogy a kódrészlet olyan paramétereket is tárol a posztokat illetően, mint hogy:
- a szerző Elon,
- a szerő power user,
- a szerző demokrata,
- a szerző republikánus.
A kód megjegyzéseiből kiolvasható, hogy ezeket az attribútumokat mindössze adatgyűjtésre használják, vagyis a posztok szűrésében elvileg nem játszik szerepet:
„Ezeket a szerzői azonosítókat kizárólag metrikák gyűjtésére használjuk. Figyeljük, hogy milyen gyakran tweetelnek ezek a szerzők, és milyen hatással vannak a bejegyzéseik a további felhasználókra.”
– áll a megjegyzésben.
Ezt az állítást persze nem lehet teljességében ellenőrizni a jelenleg elérhető kód alapján. Musk egyébként – aki állítása szerint a nyilvánosságra hozásig nem is volt tisztában ezeknek a címkéknek a létezésével – azt mondta, szerinte ilyen paramétereket nem kellene tárolni.
Korábban írtuk a témában: Elon Musk szerint a Twitter algoritmusa manipulálja az embereket
Az algoritmus mindezeken felül figyelembe veszi, hogy egy poszt több, mint 30 perce jelent-e meg, tartalmaz-e képet, vagy hogy ún. „power user”-től származik-e, ami sokak szerint azt jelenti, hogy hitelesített fiókról van szó. Ezek az információk főleg marketing szempontjából számítanak hasznosnak.
A Twitter napokkal azt követően hozta nyilvánosságra az algoritmus részleteit, hogy kiderült, a közösségi média forráskódjának nagy részét valaki feltette a GitHubra, a The New York Times szerint pedig már hónapokkal ezelőtt is elérhető lehetett. A Twitter most jogi úton próbálja kikényszeríteni a GitHubtól, hogy fedje fel a szóban forgó felhasználó adatait.